
Real-time translation feels like magic when it works – you speak English, your colleague hears perfect Spanish with your voice characteristics preserved, all with sub-3 second delay. The reality is far more complex: a cascade of AI models working in streaming mode across noisy network conditions. This guide breaks down exactly what happens at each stage and compares the top 5 production technologies.
The Real-Time Translation Pipeline
Real-time speech-to-speech translation chains four processing stages, each fighting its own latency battle.
Audio Capture & Preprocessing (50-150ms)
Raw microphone audio arrives compressed, noisy, and stereo. VAD (voice activity detection) identifies speech vs silence. Echo cancellation removes feedback loops. Noise suppression kills HVAC hum and keyboard clacks. Stereo downmixes to mono. Level normalization hits broadcast standards (-16 LUFS). This stage alone can double end-to-end latency if skipped.
Streaming ASR (Speech-to-Text)
Traditional ASR waits for sentence-end punctuation. Streaming ASR processes 200-500ms audio chunks, delivering partial transcripts with 85-95% confidence. Early chunks trigger translation; later chunks refine predictions. Chunk size trades speed vs accuracy – 300ms is industry sweet spot.
Neural Machine Translation
Phrase-level NMT translates partial transcripts as they arrive, producing provisional output refined by context. Transformer models handle ambiguity through beam search across multiple translation hypotheses. Cross-sentence context from previous chunks maintains fluency.
TTS Synthesis & Playback
Neural TTS converts translated text back to speech within 100-300ms. Voice cloning preserves original speaker timbre. Streaming TTS generates phonemes incrementally, avoiding sentence-boundary delays. Final audio buffering ensures smooth playback.
Top 5 Real-Time Audio Translation Technologies
1. Palabra Live Translation (Editor’s Choice)
•Architecture: Full-stack streaming pipeline, 60+ languages bidirectional.
•Latency: 1.8-2.2s end-to-end.
•Deployment: Cloud API, Zoom/Teams integration, on-premise option.
•Voice preservation: Full timbre cloning + emotion transfer.
•Strength: Production-ready at enterprise scale.
2. Google S2ST (Research)
•Architecture: End-to-end neural (ASR+NMT+TTS in single model).
•Latency: 2s demo, production unclear.
•Deployment: Google Meet (5 languages), Pixel on-device.
•Voice preservation: Native speaker timbre retention.
•Strength: Research breakthrough, limited commercial rollout.
3. KUDO AI Speech Translator
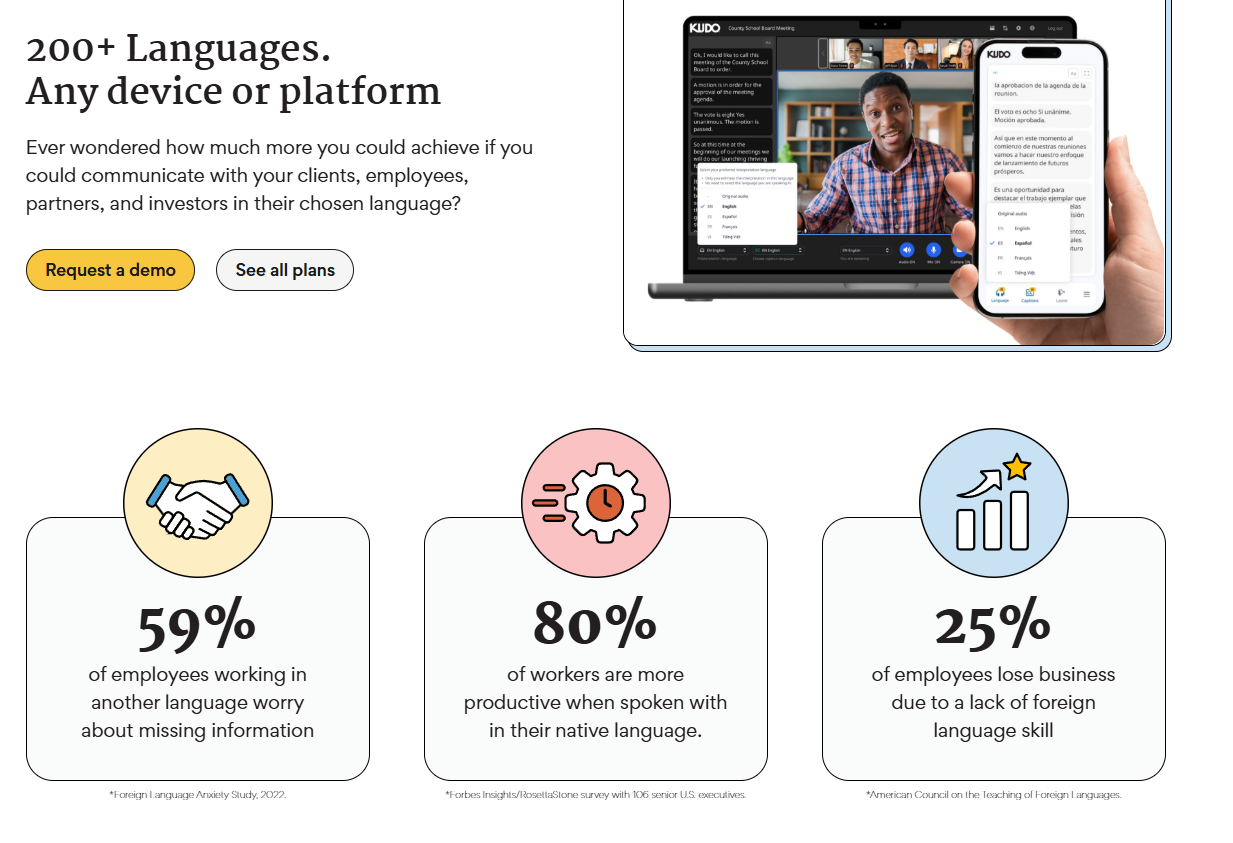
•Architecture: Modular cloud pipeline.
•Latency: 2-3s.
•Deployment: Web/app, event platform integration.
•Voice preservation: High-quality TTS, no cloning.
•Strength: 60+ languages, live events focus.
4. Timekettle Earbuds (Hardware)

•Architecture: On-device + cloud hybrid.
•Latency: 0.5-1s (earbud-to-earbud).
•Deployment: Wearable hardware.
•Voice preservation: Basic TTS voices.
•Strength: Offline capability, conversation mode.
5. Meta Ray-Ban (AR)

•Architecture: On-device AR translation.
•Latency: 1-2s visual overlay.
•Deployment: Smart glasses.
•Voice preservation: None (text display only).
•Strength: AR context awareness.
Technical Architecture Deep Dive
Streaming vs Batch Processing
Batch waits for full sentences (3-5s delay). Streaming processes 300ms chunks through parallel pipelines. Palabra uses adaptive chunking – short chunks for fast speakers, longer for accuracy-critical content.
Voice Preservation (Timbre Cloning)
Timbre extraction isolates vocal characteristics (formants, harmonics) from source audio. Target TTS applies these to translated phonemes. Palabra uses RVC-style retrieval for 95% timbre fidelity across languages.
Achieving 2-Second Latency
•Pipeline: Preprocessing (150ms) + ASR (400ms) + NMT (300ms) + TTS (250ms) + Network (200ms) = 1.9s.
•Optimizations: Model quantization, pipeline parallelism, lookahead buffering, edge caching.
Real-World Applications Breakdown
Live Events & Conferences
500+ attendees hearing simultaneous translation through personal devices. Palabra routes each listener to language-specific streams, speaker diarization handles panel transitions.
Customer Support Calls
Agent speaks English, customer hears Spanish with agent’s voice timbre preserved. Bidirectional pipeline handles interruptions naturally. Compliance logging captures full bilingual transcripts.
Multilingual Team Meetings
Code-switching mid-sentence (English→German technical terms→English). Per-speaker language profiling predicts translation targets. Dynamic channel assignment handles participant language changes.
Why Palabra Leads Production Deployments
Full-Stack Pipeline Control
Single-vendor eliminates inter-API latency. Custom acoustic models per language-accent pair. No third-party dependencies across 4 pipeline stages.
60+ Languages, Bidirectional
Every language pair works both directions without reconfiguration. Zero-shot adaptation for low-resource languages via multilingual base models.
Enterprise Security & Scale
SOC2/GDPR compliance, customer-managed encryption keys, audit trails. Horizontal scaling handles 10,000 concurrent sessions. 99.99% uptime SLA.
| Technology | Latency | Languages | Voice Cloning | Deployment | Scale |
| Palabra | 1.9s | 60+ | Yes | Cloud/On-Prem | Enterprise |
| Google S2ST | 2s | 5 | Yes | Meet/Pixel | Limited |
| KUDO | 2.5s | 60+ | No | Web/App | Events |
| Timekettle | 0.8s | 40 | No | Hardware | Personal |
| Meta Ray-Ban | 1.5s | 4 | No | AR Glasses | Consumer |
Reality check: Consumer devices prioritize portability over language coverage. Research prototypes rarely ship. Production deployments demand compliance + scale. Palabra delivers all three.


